Linux Processes
The instance of a program that is being executed by one or many threads is called a process. Any command that you give to your machine starts a new process. It is basically the running instance of your program, made up of instructions and sometimes with some form of input such as data from a file or user input.
While a program is a passive collection of instructions, a process is the actual execution of those instructions. A program may be run on multiple processes.
Fundamentally, we have two kinds of processes; the ones running in the background and the ones that run interactively. Background processes run automatically without expecting a user input while foreground processes are usually started and controlled through a terminal session.
We also have daemons - these are background processes that start when you boot up your machine and keep running forever, unless they are stopped.
Properties of a process
You can see the status of currently running processes by running the ps command. This command will also show you certain properties of these processes, should you ask about them by passing arguments like ps -o pid,ppid,tty,uid,args.
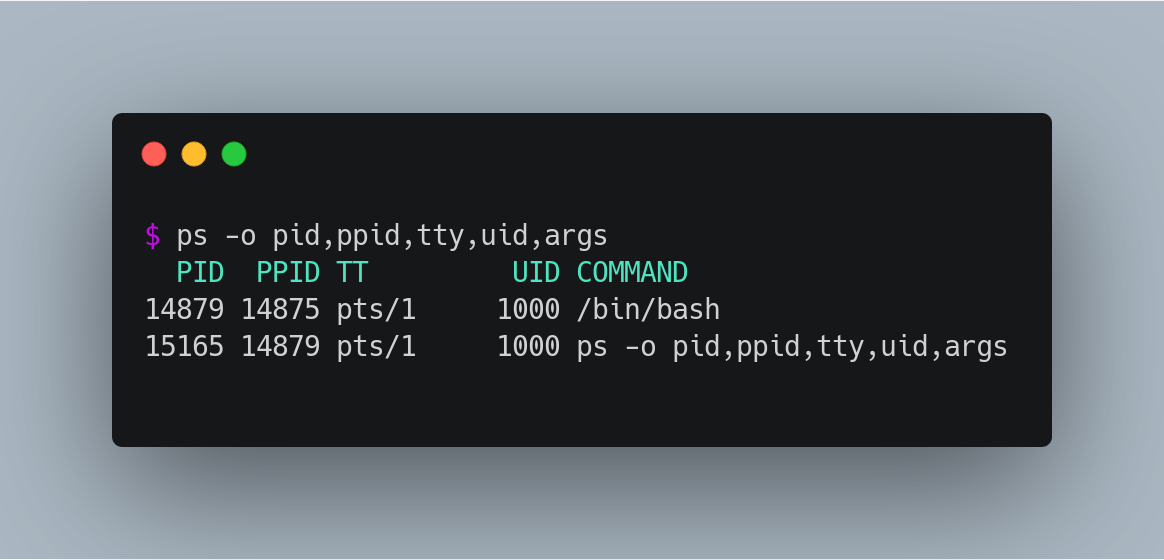
PID: Every process has a unique identifier associated to it. You can reference a specific process using their PID.
PPID: The PID of the parent process. Parent of a process is the process that was responsible for its creation. In the above example, the process for the ps command was initiated by /bin/bash, as you can see the PPID of it is same as bash PID.
TTY: The identifier of the terminal session that triggered this process. Almost every process will be attached to a terminal (except daemons). In the example above you can see that I have a terminal sessions running (pts/1). You can check your current tty by running the tty command.
UID: The identifier for the user who is the owner of this process, which will define the permissions available for this process. Run the command id -u yourUsername to check your user id.
ARGS: The command (followed by its arguments) that’s running in this process.
There are tons of properties besides the ones I’ve mentioned above, such as fname, start, cgname, class, machine, nwchan, c, %mem, pidns, pgid. Check the man ps for a long list of keywords available.
The init process
init is the first program that’s executed when the linux system boots up, so it doesn’t really have a parent process.
The Kernel, User Space and Kernel Space
The kernel is the program that controls all other programs on the computer, talking both to the hardware and software, managing resources.
A modern OS will usually isolate virtual memory into kernel space and user space, to provide memory and hardware protection from malicious behaviour.
Kernel space is reserved for running a privileged OS kernel, its extensions and most device drivers, while user space is the memory area where normal user processes (anything other than the kernel) can execute.
Processes that are running in the user space will only have access to this limited part of memory, while kernel can access all of the memory.
The Shell
A shell program is a command-line interface on a computer that allows the user to interact with the file system (a.k.a. the user space).
In most operating systems, you access the shell (eg. bash) through a terminal emulator (eg. Konsole).
To run programs and start processes, the shell needs to pass it to the kernel. Basically, the shell is your interface to communicate with the kernel.
When you run ls -l, The shell reads the command from the getline() function’s STDIN, parses the command into arguments that will be then passed to the program it is executing.
The shell checks if ls is an alias. If it is, the alias replaces ls with its value. If it isn’t an alias, the shell checks if this is a built-in command.
Then the shell will try to find a program file for this ls command. How would it know where to look for it?
The shell environment holds a bunch of environment specific variables, including a well known one that is $PATH. $PATH is a list of directories that shell can search in upon receiving a command.
You can see your environmental variables by running the printenv command.
This is how a sample$PATH would look like: PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
$PATH will be parsed using the = as the delimiter, then all the directories within the path will be tokenized and parsed further with : as the delimiter.
Most of the built-in executable programs live within /usr/bin, so the shell will find the program for ls at /usr/bin/ls location.
Most programs can take options and/or arguments. ls lists the contents found in the current working directory.
It can take a specific directory as the argument and it would then list files under that directory.
Most options actually stand for something that is longer to type. Each program defines its options (like -l for ls) and arguments (like /foo for listing ls /foo) that it will expose to users.
Most of the programs differentiate options from arguments by requiring a dash (-) or two dashes (–) before them. For some options you can define a value, like --dir=/home/username/foo.
The order of options and arguments might matter, and options come before arguments do in most cases. So if you were to run ls /foo -l in a system without GNU C library, you would make ls treat -l as another directory.
In GNU & GNU/Linux many programs will automatically treat the options as if they were typed before the arguments, so running ls /foo -l still works.
Let’s summarize what’s happening when you run ls -l.
- Shell uses
getline()to receive the user given command and it stores this into a buffer. - Shell uses
strtok()to tokenize each word found in the command using space as the delimiter. - Checks for aliases. For example,
llis an alias forls -l. When you runll, the shell will replace this with the full command. - Checks if the received command is a built-in command. This is sort of like looking a function’s definition first within the current namespace in PHP. If the program is contained within the shell itself, it’ll just run it directly.
- Search for the command within the directories found in the
$PATH, if it was not a built-in program. - The shell will use a system call
fork()to create achild processthat the program can run on, and when it’s done executing we get back to the shell. It uses the system callwait()to wait until the program operation is finalized before exiting back to the command prompt. - If the found program is executable, the shell will use the
execve()system call to execute the program in the child process. - Once the execution is complete, any returns from the program will be returned, anything the program wants to print out, like the list of directories in the current working directory, will be displayed on the command prompt.
Exit codes
An exit code is the code returned to a parent process (caller) by a child process (callee) that has finished executing. The child process exits by calling the exit syscall when it finishes executing. This syscall passes the exit status code back to the parent, which can retrieve it using the wait syscall.
On POSIX systems the standard exit code is 0 for success and any number from 1 to 255 for anything else. You can find some of the well accepted exit codes listed at the related section of the Advanced Bash-Scripting Guide.
If the child process exits and the parent somehow fails to wait, you get a zombie process. These zombie processes don’t really exist anymore, yet they will still show up in the process table with a status Z. The kernel cannot right away get rid of a process when it exits, since this would make it impossible to read its exit code, so it just waits until the parent calls wait and then it gets fully removed.
If a child process is still running, but it’s parent exits (because it crashed etc), then you get an orphan process. Orphan processes get ‘adopted’ by the init process (or launchd on Mac OS, basically the very first process executed) and their PPID will be 1.
A process can become a daemon by being made an orphan process on purpose (eg. by forking a child and immediately exiting). This is useful when you’d like to detach a long running process from your session. Usually one makes use of signals to terminate daemon processes using the kill syscall. kill actually just send a message (any message available, see kill -l), it doesn’t terminate a process by default.
With the exception of SIGKILL and SIGSTOP, processes can trap a signal to ignore it completely or to take some custom action. If Ctrl-c doesn’t kill the process, your target process probably traps it to do something before exiting.
The init process can ignore even a SIGKILL or a SIGSTOP signal, because the kernel forces a system crash if the init process terminates, so it will ignore any such signal.
System calls, interrupts and processor modes
A system call lets a program to requests a service from the kernel. They act as an interface between a process and the OS it is running on.
This could be a hardware-related request like accessing the file system, creating, executing or scheduling a new process.
In most systems, system calls can only be made from user space processes.
The architecture of most modern processors (except some embedded systems) involves a security model.
Ie. the rings model specifies multiple privilege levels under which software may be executed.
Usually all programs run in their own address space so that they aren’t allowed to access or modify other programs, devices or the OS itself.
However, many applications do need access to these components, so the OS exposes the system calls to provide safe implementations for such operations.
The OS is executing at the highest level of privilege possible and it allows applications to use system calls to request services. These are often initiated via interrupts.
An interrupt puts the CPU into some elevated privilege level automatically, then passes control to the kernel. The kernel determines whether the calling program shall be granted the requested service.
If the service is granted access, the kernel will execute a set of instructions over which the calling program has no direct control.
It will then return to the privilege level of the calling program, and return the control back to the calling program.
Usually a library or API sits between normal programs and the OS. On Unix-like systems, this API is generally part of an implementation of the libc (such as glibc), providing wrapper functions for system calls.
On Windows NT, this comes in the Native API (ntdll.dll) and it is used by implementations of the regular Windows API and by some system programs on Windows. These wrapper functions expose a function calling convention (a subroutine call on the assembly level) for using the system call. They place the arguments to be passed to the syscall in the appropriate registers and set a unique system call number for the kernel to call.
The call to the library function is usually a subroutine call, it doesn’t cause a switch to kernel mode (if the execution was not already in kernel mode).
The actual system call transfers control to kernel and it’s more implementation and platform dependent than the library call abstracting it.
E.g. in Unix-like systems, fork and execve are libc functions that invoke the fork and exec system calls.
The library functions are meant to abstract away the implementation to avoid making the system call directly in the application code. The low-level interface for the syscall operation can change over time and thus it should not be a part of the ABI.
Some known system calls (in Unix-like and other POSIX-compliant OSes) are open, read, write, close, wait, exec, fork, exit, and kill.
Many modern operating systems have hundreds of system calls. Check out syscalls page for a long list of syscalls available in Linux.
Tools such as strace, ftrace and truss allow a process to execute from start and report all system calls the process invokes. They can also be attached to a running process and intercept any system calls it is making.
This functionality is usually also implemented with a system call, e.g. strace is implemented with ptrace or system calls on files in procfs.
There are different categories of syscalls: process control (eg. fork to create a process, get/set process attributes, allocate and free memory), file management (eg. create/delete/open/close/read/write files), device management (eg. logically attach/detach devices, get/set device attributes), information maintenance (eg. get/set time or date, system data, process, file or device attributes), communication (eg. send/receive messages, transfer status info), protection (eg. get/set file permissions).
Processor Modes
Processor modes (a.k.a CPU modes, CPU states or CPU privilege levels) are operating modes for the CPU of certain architectures that place restrictions on the type and scope of operations that can be performed by processes being run by the CPU. This allows the OS to run at a higher privilege level than any other software.
Only the kernel code runs in unrestricted mode while everything else runs in a restricted mode and needs to use system calls via interrupts to ask the kernel to run operations on its behalf. However, syscalls might hurt performance or take some time, so it’s not that uncommon for system designers to allow some time-critical software (eg. device drivers) to run with full kernel privileges.
The unrestricted mode is often called kernel mode (or master mode, supervisor mode, privileged mode, etc.).
Restricted modes are usually referred to as user modes (or slave mode, problem state, etc.).
In kernel mode, the CPU can perform any operation allowed by its architecture, letting any instruction that may be executed, any I/O operation initiated, any area of memory accessed, and so on.
In other modes, certain restrictions on CPU operations are enforced by the hardware. Typically, altering the global state of the machine is not allowed and some memory areas cannot be accessed etc.